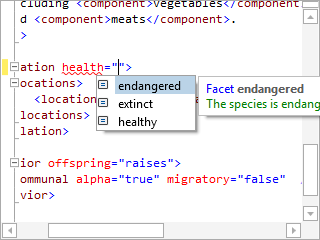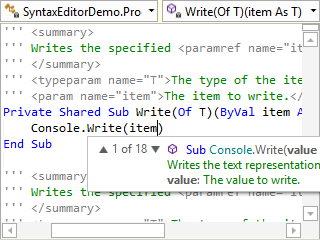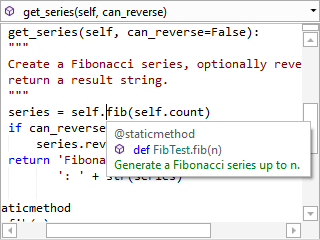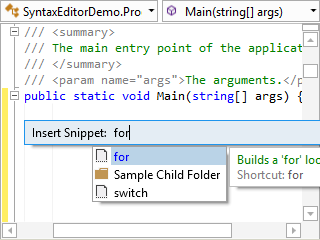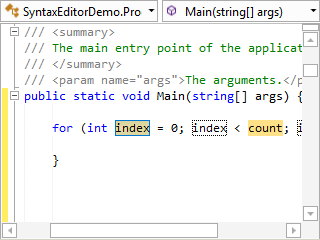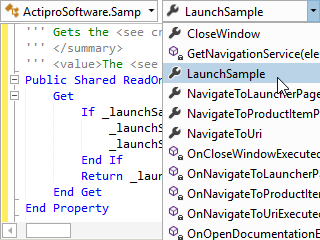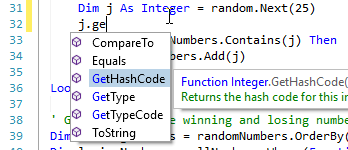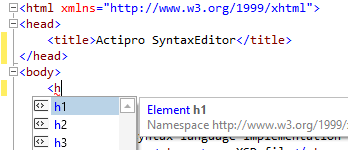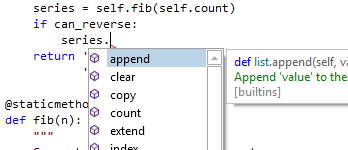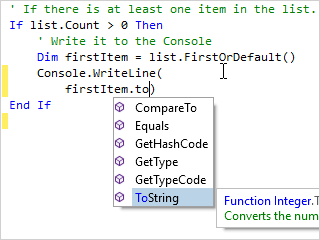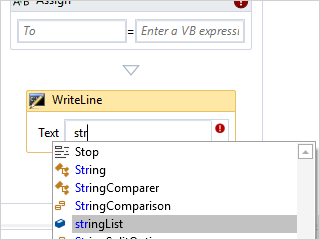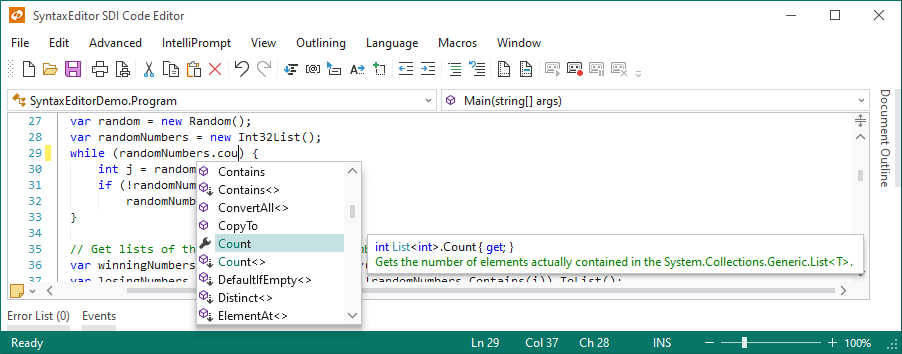
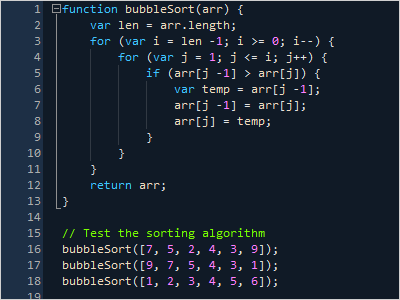
Syntax Highlighting
Highlighting styles can be completely customized by the end user for each code language. SyntaxEditor comes with syntax highlighting for over 25 languages.
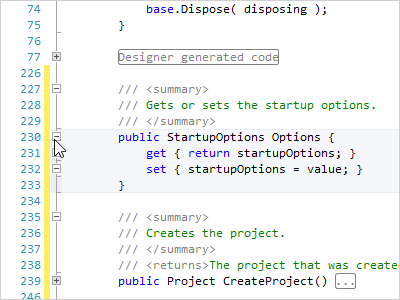
Code Outlining (Folding)
The end user can collapse ranges of text defined by the language. A small adornment represents the collapsed text, and hovering over it shows the contained text.
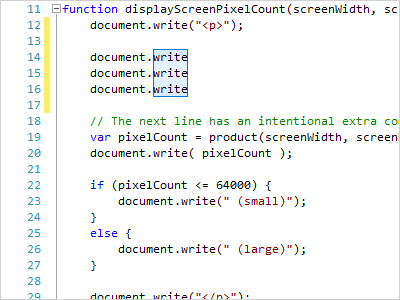
Selection Modes
While standard continuous selection mode is generally used, a special block selection mode is available that supports simultaneous editing of multiple lines.
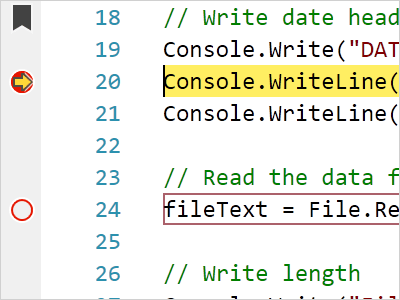
Indicators
Indicators are special 'tagged' regions of text that display a glyph in the indicator margin and optionally highlight the text range with special styles. Text range-based (e.g. breakpoint) and line-based (e.g. bookmarks) indicators are supported.
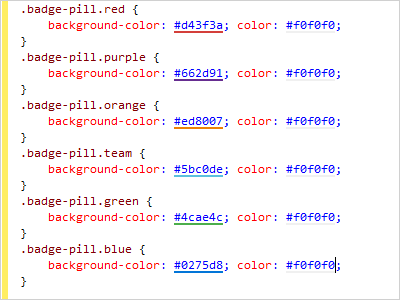
Adornments
A powerful adornment layer system allows for any sort of custom UI elements (images, shapes, and even controls) to be added anywhere within the text area. Easily add squiggle lines, background highlights, or any other decoration to text.
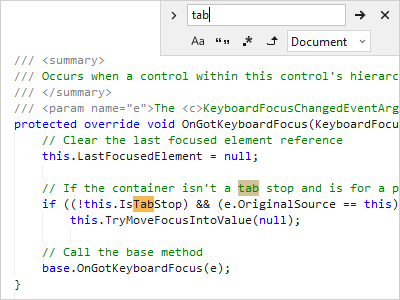
Search (Find/Replace)
A flexible search API is built into the control with the ability to highlight matches. End users can use incremental search to search without UI, or our search view control that has a ready-to-go find/replace user interface.
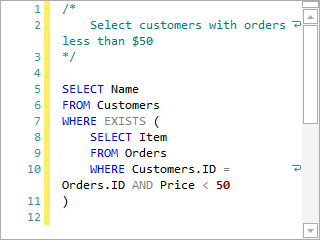
Word Wrap
When word wrap is enabled, long lines will wrap at the editor view's edge to a new line so that all text can be visible without horizontal scrolling.
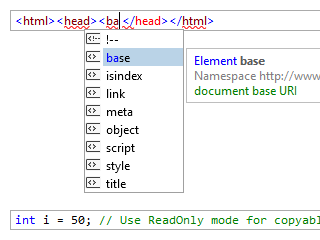
Single-Line Mode
An optional single-line mode renders the control like a regular TextBox, but with all the syntax-highlighting, selection, IntelliPrompt, and other features that make SyntaxEditor great.
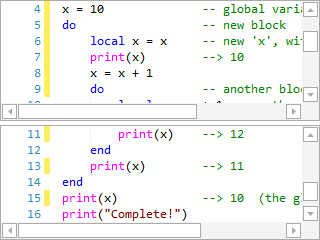
Split Views
Split the editor into multiple resizable views so that different portions of the same document can be viewed and edited in the same editor control.
Undo and Redo
Edits to a document are tracked in undo and redo stacks, allowing an end user to backtrack to an earlier version of the document's text.
Block Indent/Outdent
Select multiple lines and press Tab to block indent them to the next tab stop, or Shift+Tab to outdent them.
Visible Whitespace
Tab and space characters can optionally be represented by glyphs that show which character generated whitespace.
Delimiters
Languages can easily support delimiter (bracket) highlighting and delimiter auto-completion.
Drag and Drop
Drag and drop text within the editor view, or externally to/from other applications where you can determine the drop's textual representation.
Margins
Line number, outlining, selection, ruler, and word wrap editor view margins ship with the control. Custom margins can be created as well.
Printing
Built-in dialogs support configurable document printing. Document title, line number, word wrap glyph, and page number margins are included.
Bi-Di Editing and IME
All text is edited in Unicode characters and bi-directional editing is fully supported. IME can be used to input extended character glyphs.
This product is fully-loaded with additional advanced features like over 100 edit actions, line modification marks, commenting/uncommenting, auto-case correct, current line highlighting, read-only regions, code block selection, mouse wheel zooming, clipboard operations, a default context menu, macro recording and playback, text statistics, export to HTML/RTF, and much more.